
2022-10-02-【迁移】基于NMF分解的降维聚类.md 2.3 KB
title: 【迁移】基于NMF分解的降维聚类 urlname: ji-yu-NMF-fen-jie-de-jiang-wei-ju-lei date: 2022-10-02 17:28:30
tags: nmf
安装补充包
- conda activate seurat
- conda install -c conda-forge r-nmf -y
- conda install -c conda-forge r-fastica -y
获取非负表达矩阵
使用《使用metacell进行分群聚类》中的数据
sce <- readRDS('SRX8890106.rds')
sce@meta.data <- readRDS('SRX8890106_meta.rds')
# 某个群进行细分
sce <- subset(sce, seurat_clusters == 6
& DF.classifications_0.25_0.04_416 == 'Singlet')
# 取项目子集后重新标准化
sce <- Seurat::SCTransform(sce, vst.flavor = "v2", assay = 'RNA',
vars.to.regress = c("CC.Difference", "percent.mt", "percent.rp"),
verbose = F)
# Seurat::PrepSCTFindMarkers
# 获取非负矩阵
DefaultAssay(sce) <- 'RNA'
sce <- Seurat::NormalizeData(sce)
sce <- Seurat::ScaleData(sce, do.center = F, # NMF 要求非负矩阵
# vars.to.regress = c("CC.Difference", "percent.mt", "percent.rp"),
features = Seurat::VariableFeatures(sce, assay = 'SCT'))
vm <- sce[[Seurat::DefaultAssay(sce)]]@scale.data
NMF分解聚类
saveRDS(vm, 'vm.rds')
vm <- readRDS('vm.rds')
require(NMF)
res <- NMF::nmf(vm, 2:7, method = "snmf/r", seed='ica')
plot(res)
## 更推荐使用Seurat的分群走向判断分群数量
require(NMF)
res <- NMF::nmf(vm, 4, method = "snmf/r", seed = 'ica')
DefaultAssay(sce) <- 'SCT'
sce <- Seurat::RunPCA(sce, assay="SCT", verbose = FALSE)
sce@reductions$nmf <- sce@reductions$pca
sce@reductions$nmf@cell.embeddings <- t(coef(res))
sce@reductions$nmf@feature.loadings <- basis(res)
sce <- RunUMAP(sce, reduction = 'nmf', dims = 1:4) # 和分群数量一致
group <- predict(res)
sce$nmf_group <- group[colnames(sce)]
options(repr.plot.width = 6, repr.plot.height = 6)
DimPlot(sce, reduction = "umap", label = T, repel = T,
group.by = c('nmf_group'))
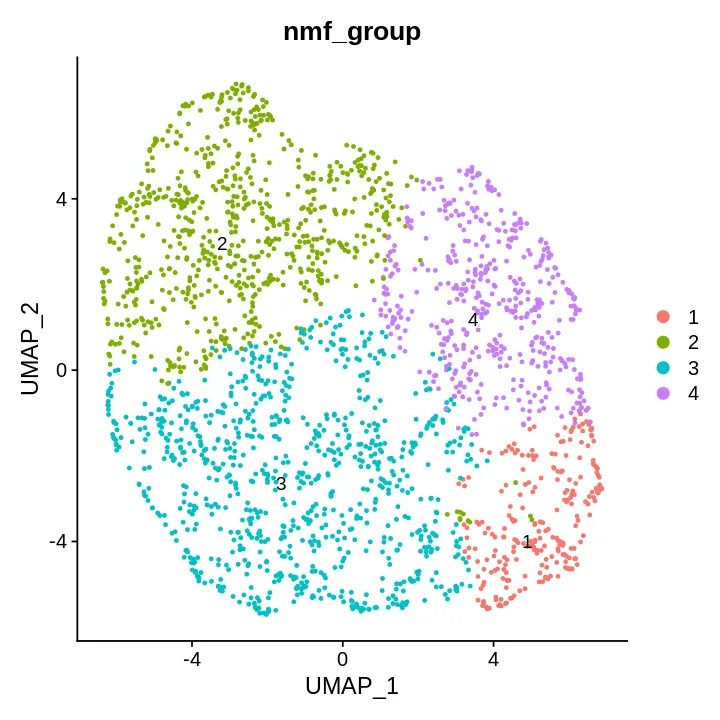
提取signatures
coefmap(res)
consensusmap(res) # 可能要设置nrun才有?
df <- extractFeatures(res, 20L)
df <- lapply(df, function(x){rownames(res)[x]})
df <- as.data.frame(do.call("rbind", df))
df