
2024-11-10-【探索】使用-qdrant-进行向量检索.md 11 KB
title: 【探索】使用 qdrant 进行向量检索 urlname: using-qdrant-for-vector-retrieval index_img: https://api.limour.top/randomImg?d=2024-11-10 04:43:15 date: 2024-11-10 12:43:15
tags: [docker, rag]
Qdrant 是一个开源的向量数据库,专为高性能相似性搜索和机器学习应用而设计,比 Chroma 更轻量(约80MiB)更快。它支持基于余弦相似度、欧氏距离等多种相似性度量的向量检索,并提供了灵活的过滤和分组功能。Qdrant 使用 Rust 语言编写,具有高效的索引和存储机制,能够快速处理大规模向量数据,适用于推荐系统、语义搜索、图像相似性匹配等场景。它提供了简单易用的 API,支持 gRPC 和 REST 接口,并且可以轻松集成到各种编程语言和机器学习框架中,是构建向量相似性搜索应用的理想选择。
部署
-
mkdir -p ~/app/qdrant && cd ~/app/qdrant && nano docker-compose.yml wget https://raw.githubusercontent.com/qdrant/qdrant/refs/heads/master/config/production.yaml sudo docker compose up -d sudo docker compose logsservices: qdrant: image: qdrant/qdrant:latest restart: always expose: - 6333 - 6334 - 6335 volumes: - ./qdrant_data:/qdrant/storage - ./production.yaml:/qdrant/config/production.yaml networks: default: external: true name: ngpm
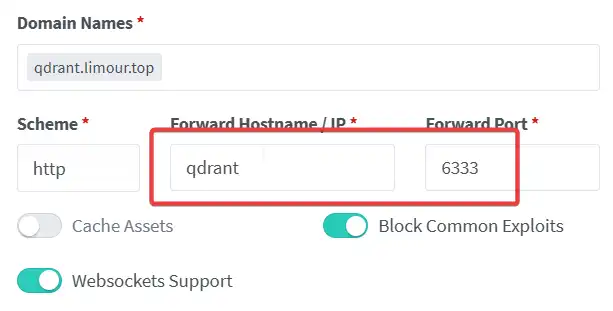
- 访问
https://qdrant.limour.top/dashboard查看仪表盘
嵌入
- 下载 llama.cpp
- 下载
cudart-llama-bin-win-cu11.7.1-x64 - 下载对应后缀的
llama-b4061-bin-win-cuda-cu11.7.1-x64 - 将两者解压到同一个目录
- 下载
- 从 MTEB 上找一个良好的嵌入模型
- 下载 GGUF 格式的嵌入模型,比如 Dmeta-embedding-zh-small-GGUF
根据文档配置参数启动嵌入服务
./llama-server.exe -m ./embd/Dmeta-embedding-zh-small-Q4_K_M.gguf -c 1024 --embedding -fa -ngl 99 --port 8080测试嵌入模型
$headers = @{ "Content-Type" = "application/json" "Authorization" = "Bearer no-key" } $body = @{ "input" = @("hello", "world") "model" = "GPT-4o" "encoding_format" = "float" } | ConvertTo-Json $response = Invoke-WebRequest -Uri "http://localhost:8080/v1/embeddings" -Method Post -Headers $headers -Body $body echo $response.Content
重排
为了在千万级数据上进行检索,返回的结果牺牲了一定的精确度,同时双端的 embedding 模型也不如单端的 rerank 模型精确,因此检索后的结果还需要进行一次重新排序。
- 下载 GGUF 格式的重排模型,比如 bge-reranker-v2-m3-GGUF
启动模型
./llama-server.exe -m ./rerk/bge-reranker-v2-m3-Q4_K_M.gguf --reranking -fa -ngl 99 --port 8081测试嵌入模型
$headers = @{ "Content-Type" = "application/json" "Authorization" = "Bearer no-key" } $body = @{ "documents" = @("hi", "it is a bear", "world", "The giant panda (Ailuropoda melanoleuca), sometimes called a panda bear or simply panda, is a bear species endemic to China.") "query" = "What is panda?" "top_n" = 3 "model" = "GPT-4o" } | ConvertTo-Json $response = Invoke-WebRequest -Uri "http://localhost:8081/v1/rerank" -Method Post -Headers $headers -Body $body echo $response.Content
客户端
conda create -n rag conda-forge::qdrant-client
获取测试所用内容 test_rag_qdrant
import os from qdrant_client import QdrantClient from qdrant_client.models import VectorParams, Distance from qdrant_client.models import PointStruct from m98_rag import embd, readChunks, rerank QDRANT_URL = os.getenv('QDRANT_URL', 'http://localhost:6333') QDRANT_KEY = os.getenv('QDRANT_KEY', '') client = QdrantClient(url=QDRANT_URL, api_key=QDRANT_KEY, timeout=100) class Hits(list): def __init__(self, hits, query_: str, limit_: int): super().__init__(hits) self.query = query_ self.limit = limit_ self.res = None def rerank(self): if self.res is None: hits = [hit.payload['text'] for hit in self] self.res = rerank(hits, query_=self.query, top_n_=self.limit) return self.res def top(self, top_n=3, related_=True): res = self.rerank() if related_: return [hit[0] for hit in res[:top_n] if hit[1] > 0] else: return [hit[0] for hit in res[:top_n]] def print(self): return ('\n' + '=' * 50 + '\n').join(self.top()) class RAG: def __init__(self, collection_name="my_collection", vectors_size=768): self.collection_name = collection_name self.vectors_size = vectors_size if not client.collection_exists(self.collection_name): client.create_collection( collection_name=self.collection_name, vectors_config=VectorParams(size=self.vectors_size, distance=Distance.COSINE) ) def upsert(self, chunks_: list, ID_: int = 0): for i in range(0, len(chunks_), 8): batch = chunks_[i: i + 8] print(batch) vectors = embd(batch) client.upsert( collection_name=self.collection_name, points=[ PointStruct( id=ID_ + i + idx, vector=vector[1], payload={"text": vector[0]} ) for idx, vector in enumerate(vectors) ] ) def size(self): count = client.count(collection_name=self.collection_name) print(self.collection_name, 'size:', count.count) return count.count def clear(self): client.delete_collection(collection_name=self.collection_name) client.create_collection( collection_name=self.collection_name, vectors_config=VectorParams(size=self.vectors_size, distance=Distance.COSINE) ) def search(self, query_: str, limit_: int = 5): query_vector = embd([query_]) hits = client.search( collection_name=self.collection_name, query_vector=query_vector[0][1], limit=limit_ # Return 5 closest points ) return Hits(hits, query_, limit_) if __name__ == '__main__': print(QDRANT_URL) print(QDRANT_KEY) test = RAG() if test.size() <= 0: chunks = readChunks('./test.md') test.upsert(chunks) tmp = test.search('机器人限拥令是什么') print(tmp.print())所得到的结果还不错~
24小时客服在线电话:1919-114514810 *注意:根据《国家质量标准认证iso7002》,《机器人管理条例》,机器人类产品不宜连续使用超过十五年。请定期到指定售后地点进行重置。 ## 十三 机器人限拥令的实施开端于2090年5月的一起案件。 被害人约翰逊的尸体在其失踪的次日被发现于他自家的住宅。死状相当惨烈:在R级新闻团体才能合法展示的照片中,整个人被从身体中间沿着脊椎切割成两半,一半被他所购买的机器人ct13694582(型号为玛格丽特c6)紧紧抱在床上,另一半被他购买的另一台机器人ct12487967(型号为子矜7z)小心的存放在冷库里。案件现场几乎满地都是受害人的血,散发着浓烈的腥味,而身为罪魁祸首的两台机器人,一台已经关机,另一台则刻板地重复着几个动作。 根据记录,两台机器人和受害人共处的时间分别长达18年和17年。在这么长的时间里,受害人以近乎均等的时间使用二者,并不下数百次的分别向它们倾诉 我最爱的是你 我只爱你一个人 你比她漂亮多了 等明显带有示爱情绪的情话。 ================================================== 所以,当别的机器人可以随意更换外观,模拟他人人格,构造全息幻象时,她还是只能用老旧的芯片链接一般的网络,在老掉牙的网站上寻找几个能逗主人开心的笑话。 望着远处飞来飞去的垃圾车,他把烟掐掉,踩灭, 哪怕是半个月前,零件黑市还没有倒闭的时候,我都还会考虑继续把你放在家里供着……可是现在,你这种型号的备件都已经买不到了,我只能选择……放弃。 如女子潮红面颊的晚霞浸透了半边天空,晚风中他回忆着有关她的那些细节。 PR3-7150家庭型机器人,东湾半导体与电子技术有限公司研发,远海机器承制,2069年第一次发售,第二年夺得电子家用商品年度大奖……而如今,则是无人问津的古董。她的编号是ct34679158,款式是茉莉白。她在前主人的家里任劳任怨地干了18年,因满身故障而被随手丢掉。之后又被他的父母在地摊上买下。此后不久,机器人限拥政策便开始实施了。 和外人说话时,他往往称她为 那倒霉玩意儿 ,不过私下里,他总是叫她的名字——爱尔莎。 ================================================== 机器人心理学中把机器人的这种行为称之为 情绪过载 。早期机器人的情感矩阵尚不足以自我解决情感函数和外部计算之间的冲突,最终导致模拟情绪的数值极化和内存溢出。用大家熟悉的名词来说——机器人也会争风吃醋。 机器人管理委员会迅速意识到,多台机器人的集群化使用或许会导致系统的混乱现象,从而使其逐渐失控。 次年,机器人限拥条例公布,社会一片哗然。 不过,贯穿条例诞生始终的是,公众的大部分兴趣都集中在了机器人病娇、机器人吃醋、机器人销毁、智能板块这样的话题上。只有很少的一部分人提及: 这是不是意味着,机器人也会懂得,什么是爱? 以及如果是,那么我们该怎样去爱它们? ## 十四 他一遍遍的把爱尔莎的人格芯片取出来调试,又一遍遍放回去。 如此重复。 ………… 直到有一天晚上他感到自己失魂落魄,整个世界失焦一般的远去。此时,他才想起来自己已经有相当一阵子没和别人说过话。 把芯片放在一边,打开了命令模式的爱尔莎。TODO
使用
NLTK||spaCy等优化切分 chunks 时的精确度。